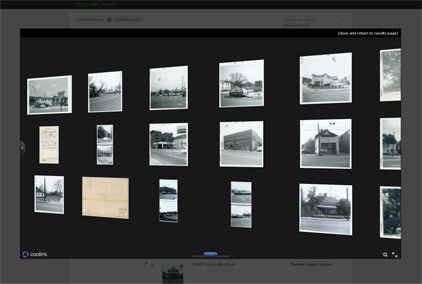
- “I can see the word on the page, but when I search for it, no matches are found.”
- “This item is searchable. Why can’t I read it with a screen reader?”
We get a lot of great questions like the ones above: the answer to all of them, in some way, is “OCR.”
What OCR Is
Optical Character Recognition (OCR) is amazing technology; with OCR software we are able to search image files for groups of pixels that look like text, guess what that text might be, and save the output in a way that we can feed into our search indexing systems. Even better, we’re sometimes able to overlay that text output on top of an image so that we can show you where we think a word might appear.
At the North Carolina Digital Heritage Center, we scan and store digital heritage materials as images. When we notice that an image contains printed text–documents, posters, ledgers, scrapbooks, and more–we also run it through OCR software. Without OCR, text shown in images is “locked” inside them; with OCR we can leverage the power of full text search to help people discover relevant images a little better than before.
What OCR Isn’t
No OCR method is without limitations. Whether OCR software can correctly “read” the text in an image depends on a few things:
The longer OCR takes, the better it is
The longer the OCR engine is allowed to puzzle over the pixels in an image, the better its output can be. At NCDHC we try to find the right balance between giving the OCR software enough time to produce useful results, and scanning more materials: letting OCR take too long would significantly reduce the amount of materials we’re able to add to DigitalNC each day.
OCR is less accurate with historic materials
Most of the materials we work with are difficult for OCR engines to interpret: compared with more modern materials, historic documents use fuzzier printing methods, display a lot of variation in letter forms, are deteriorating, or contain a mixture of printed and handwritten text. All of these things are likely to confuse even the best OCR software, producing text output that can differ from what’s visible on the screen.
OCR isn’t the same as a transcription
Without human intervention, it can be difficult for OCR software to interpret the layout of a document. By default, OCR software attempts to “read” an image from left to right. Even if it’s able to recognize all of the words on a page, it may not recognize the order in which the words were intended to be read; for example, the software might not be able to differentiate where one column ends and another begins in a newspaper clipping, or it might include the text of an advertisement in the middle of an article:

In contrast, transcriptions represent the text in an image as it’s meant to be read, and requires some amount of human labor to produce.
Summary, and a look ahead
OCR is a fantastic tool that enhances the way users are able to interact with the images available in DigitalNC collections, but its limitations prevent it from producing full, traditionally-readable transcriptions of image materials.
Even so, NCDHC looks forward to next-generation tools and methods for recognizing and searching for text within images. OCR software is constantly improving; the software we use today is faster and more accurate than it was five years ago, and OCR technology benefits from recent advances in machine learning and artificial intelligence.
If you have questions or concerns about searchable content on DigitalNC, or would like information on obtaining a copy of materials that is accessible to screen readers, please don’t hesitate to contact us.