Vertical files are groups of subject-based materials often compiled over time to help an organization’s staff with frequent reference questions or research. Like the example above at Shepard-Pruden Library in Edenton, NC, they’re typically housed in filing cabinets. They are a good place to store items that wouldn’t necessarily be cataloged or accessioned (individually and formally documented by the institution) but are valuable for research. Inside you might find photographs, clippings, family trees, pamphlets, handwritten notes – but because the contents accumulate over time you can find any number of surprises inside.
Vertical files are groups of subject-based materials often compiled over time to help an organization’s staff with frequent reference questions or research. Like the example above at Shepard-Pruden Library in Edenton, NC, they’re typically housed in filing cabinets. They are a good place to store items that wouldn’t necessarily be cataloged or accessioned (individually and formally documented by the institution) but are valuable for research. Inside you might find photographs, clippings, family trees, pamphlets, handwritten notes – but because the contents accumulate over time you can find any number of surprises inside.
Vertical files are also the worst – for digitization that is. The same thing that makes them valuable for research – their convenience, their long term growth, and the variety of contents – makes them incredibly challenging to scan. If you’re interested in digitizing vertical files, we have suggestions! These have been compiled from our own experience at NCDHC along with the experiences of a number of our partners who kindly responded to a recent email asking for advice.
When facing full filing cabinets you may be tempted to dive in right at the beginning and get going, but we always suggest starting with a pilot project using a subset of materials. We can’t emphasize this enough! It’ll give you a sense of workflow, help you establish how you’re going to name and organize the scanned files, and uncover obstacles you didn’t anticipate. If it goes poorly, you can back out without losing a large investment. The suggestions below can be used for a pilot and for a full-fledged project.
Suggestion 1: Prep First, Thank Yourself Later

Here’s an example of a vertical file with newspaper clippings, letters, and publications about World War II. From the collection at Shepard-Pruden Library in Edenton.
Scan it all or be selective? Decide if you want to go from beginning to end or to be selective about what you’ll scan. There’s no right answer but each way has ups and downs. This decision will be subject to your users’ needs and your local resources.
Scan it all? Is there enough high value and unique content in your vertical files to warrant scanning everything? For example, some newspaper titles have been digitized in their entirety and are full text searchable (like those available at DigitalNC or Chronicling America) so you might decide that scanning clippings from those same papers is superfluous. As another example, many books published before 1924 in the United States are available online at the Internet Archive or through a simple search in your internet browser. If your files have a lot of book excerpts you may want to skip those.
Be selective? Being selective can be more time consuming and you may unintentionally miss items that would be of use, but it can be appropriate if you’re trying to simply scan items related to one or two topics or for a particular event. It is also a great option if you don’t have a lot of time or resources but want to help give access to high demand files.
First pass for organization. Go through the files in a first pass, during which you’ll assess the files’ contents, sort them in a way that will make scanning easier, and prepare the different formats for scanning. Here are some tasks to complete as you make a first pass:
- Pull out items to be cataloged separately. As your organization’s collection strategies have changed over time you may find materials within the files that should be pulled out and cataloged or accessioned independently. For example, perhaps you are a library where pamphlets were previously stuck in vertical files but are now cataloged and put on the shelf. These can be pulled out and dealt with separately.
- Weed. Take this opportunity to weed out duplicates and look for misfiled items.
- Group items with copyright or privacy concerns. I talk about this in more detail below, but if you plan to put these files online, you may want to skip scanning items that would be too risky or unethical to share online. You could put them towards the back of each file with a divider that indicates they should be either reviewed in more detail or skipped while scanning.
-

Ashlie, an NCDHC staff member, uses a microspatula to pry up staple legs. License: CC0
Remove staples and fasteners. The caveat here is that you should only do this with materials you’re sure you’re ready to scan. One partner mentioned that staff had removed staples and paperclips from a large quantity of files, but then the project got stalled. Because the vertical files were still in use, this led to papers being misfiled, shuffled out of order, and lost.
- Organize by type then by date. Within each file, organize individual items first by format of item, then by date. Group all of the photographs. Put like sized publications together. Group all of the single page items, all of the clippings. Putting like sized types together will speed up the workflow, saving time when scanning by streamlining your efforts at cropping. Once you’ve grouped things by type, within each group put things in date order (if dates are available). This will help you when you make the scans available.
Suggestion 2: Prepare for the Digital Files
Unless you don’t have that many vertical files (or you have a LOT of time and help) think of each vertical file as a single unit. Here’s what I mean by this. If you have a vertical file about a popular local landmark called the “Turtle Log,” and it includes a few photos, some clippings, and a handwritten narrative, all of those scans would be kept together in a virtual group, folder, or album just as they are in real life. When you describe that group/folder/album either in an internal or online database, you’d describe the unit as a whole, rather than describing each individual photo, clipping, or narrative. This will save a ton of time.
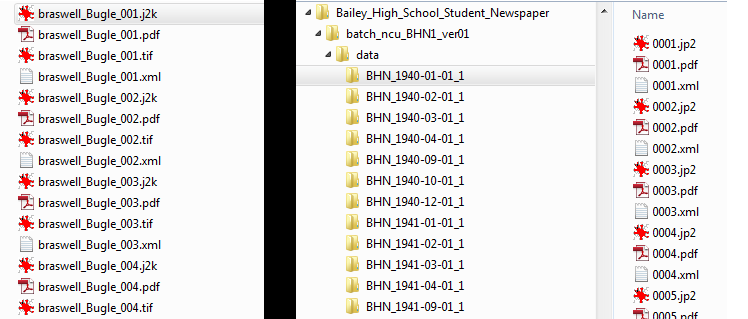
 With this in mind, you’ll want to think of a file naming scheme that will keep all of these digital groups organized. Thankfully, file systems mimic files in real life, with the use of folders. Make sure you have a consistent naming convention for files and folders that ensures everything sorts appropriately. On the right is a quick example of how you might decide to name your files. This example is very basic – you could choose to give more detail, include known dates. But note the numbers (01, 02, etc.) included that will make the files sort in order.
With this in mind, you’ll want to think of a file naming scheme that will keep all of these digital groups organized. Thankfully, file systems mimic files in real life, with the use of folders. Make sure you have a consistent naming convention for files and folders that ensures everything sorts appropriately. On the right is a quick example of how you might decide to name your files. This example is very basic – you could choose to give more detail, include known dates. But note the numbers (01, 02, etc.) included that will make the files sort in order.
Suggestion 3: Determine How You’ll Work with Additions
If you intend to keep these vertical files active after scanning, you’ll need to figure out how to denote what’s been scanned and what you’ll do with new additions to the files. A light pencil mark or some other non-permanent note on the back of all scanned items can signal what’s been scanned. Decide if you have the time and staff to scan new additions before filing new donations or if you plan to do that wholesale at a later date. It might also be helpful to have a marker of some sort that you can insert into the file cabinets that lets researchers and staff know about files that have been removed for scanning and whether or not they can still request them.
Suggestion 4: You Should Scan these In House. Or You Shouldn’t.
I wish I could give a single way forward here, but like so many things the answer to whether or not to outsource scanning depends on your situation. Here are a few considerations for the two routes.
Scanning in house. This gives you a lot of flexibility. You can work on the project over time. For active files, they’ll be close at hand if needed. Your staff will gain experience scanning, if they don’t already have it.
Unless you can afford an overhead scanner or camera mount setup, scanning vertical files on a flatbed or other multifunction machine will make a very long process a lot longer. Sheetfed scanners can speed things up a little but only for extremely uniform, non-unique materials that are in good shape. Because the project is large, if you don’t have dedicated scanning staff (or even if you do) be prepared for the contents of multiple file cabinets to take years to scan. You may also need to hire new staff or reskill current staff to do this work, trading this for other duties they currently complete.
Outsourcing scanning. Outsourcing can mean a quicker outcome because the organization doing the scanning will have dedicated workflows and equipment for high volume output. If you don’t have digitization expertise on staff, their expertise can be helpful for avoiding pitfalls.
Unless you are working with an organization that typically scans special collections, the variety of formats can be a challenge and frequently increase the cost. Companies that specialize in corporate files will claim attractively inexpensive prices for scanning but they are frequently used to working with homogenous typing or copy paper. Be sure to interrogate them regarding their expertise, showing them examples and even asking for a quote after they scan a subset. Make sure they offer digital files of a quality and in file formats that you can use into the future.
Suggestion 5: Decide About Your Access Priorities and the Rest will Follow
As we’re fond of saying, digitization is the easy part. Even in a project of this size and complexity, the scanning and preparation of the digital files is more straightforward then what comes next. Here are confounding factors to take into account when you consider how you’ll provide access to the digital vertical files.
 Full Text Search
Full Text Search

Full text search greatly increases the usefulness of digital vertical files. It’s one of the most cited reasons for scanning them in the first place. To be able to search full text within a scanned document, you’ll need to run that digital file through software that recognizes the text and then either embeds it within the file or stores it separately. (Note that this will only happen with typewritten text – accurate automated recognition of handwriting isn’t widely available at this point.) Here are two different options:
- Some institutions choose the PDF format for their vertical files. Software like Adobe Acrobat (not to be confused with the freely available Adobe Reader) will recognize text within a PDF. However PDFs are made for easy transmission and sharing, not for longevity and quality. We recommend that you scan initially to a higher quality or lossless format, and then, if it fits your goals and resources, create derivatives like PDFs. The upside of PDFs is that many desktop and laptop computers can natively search across PDFs. This means you could have them searchable locally, say on a reading room computer, and not necessarily have to provide internet access.
- Alternatively, you can use a system that can store both the text recognized in an image and the image itself and then link them together. Some library or museum catalogs will do this, or you’ll need a content management system. This means additional ongoing costs and the need for technological infrastructure and expertise. But with these types of systems you can provide full text search of your files on the internet.
Copyright and Privacy
Copyright is one of the biggest confounding factors related to making vertical files accessible. Depending on how old your files are, it’s likely that there are materials in there that will be in copyright. If you want to post copyrighted materials on the internet, your organization will need to assess the amount of risk you’re willing to accept. Some items are riskier than others. Regardless, whoever is working on your vertical files will need training and the authority to determine what can and should go online and what should not. Here are a few resources to help get you started:
- Library of Congress – Understaning Copyright (though targeted at people who want to use items on the Library of Congress’ website, this is a good overview of points to consider)
- Association of Research Libraries Code of Best Practices for Fair Use for Academic and Research Libraries (even if you’re not an Academic or Research Library there are a lot of good best practices here)
- Cornell University Library’s Copyright Term and the Public Domain in the United States Chart (a quick table that acts as an easy reference for figuring out the applicable term of copyright for your item)
In addition to copyright, you should always consider privacy concerns. For some of the non-published items in your vertical files, the donations or additions were made with the expectation of local use by a single person or small group. Family history documents that discuss recent events are an example of the type of item you may judge to be too personal for broad consumption without the permission of the creator. There may be documents that share information about communities that would prefer they not be shared broadly. These are all good things to assess as you do your first pass.
Suggestion 6: Find Examples and Friends
Here are some examples of digitized vertical file collections online. These are large projects with a goodly number of staff and funding involved, so take that into account as you look. Note that the files are put online whole rather than breaking out individual items.
This first example comes from the Digital Collections of the University Libraries at UNC-Greensboro and showcases their “class folders.” UNC-G has done quite a bit with vertical files of various types, but this is a great example of folders that have a variety of items grouped by subject. These items are in a system called CONTENTdm, which is specifically designed to host special collections.
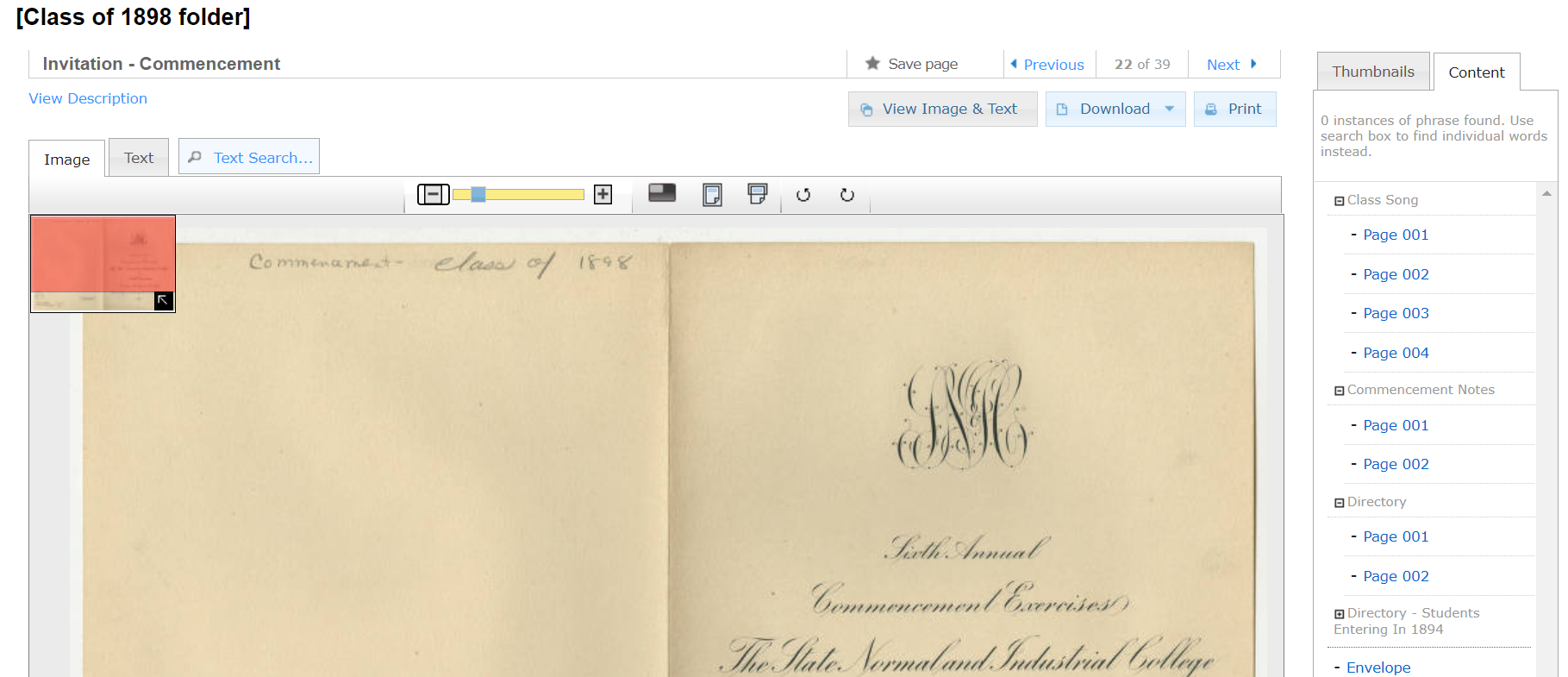
This invitation is one of a number of items in the vertical file entitled “Class of 1898.” You can see the item title at the top and a list of the different items inside on the right.
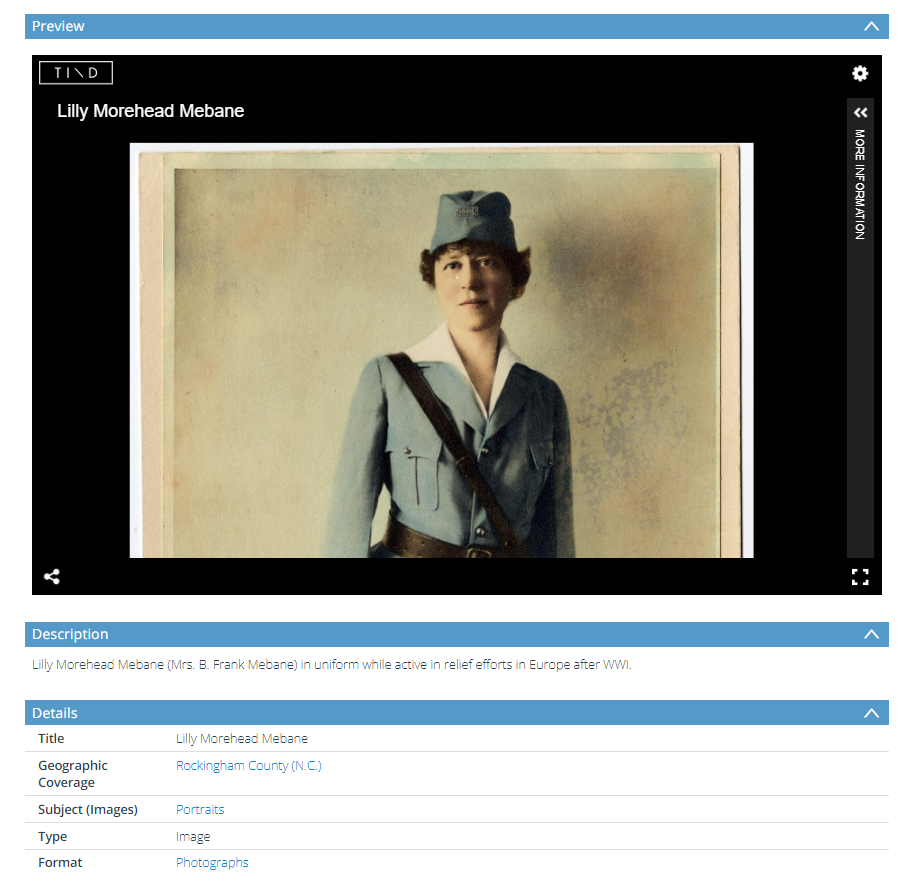
We’ve also done some vertical files at NCDHC, and you can take a look at an example here. This is from a large collection of vertical files shared by the Kinston Lenoir-County Public Library. Our system is called TIND.
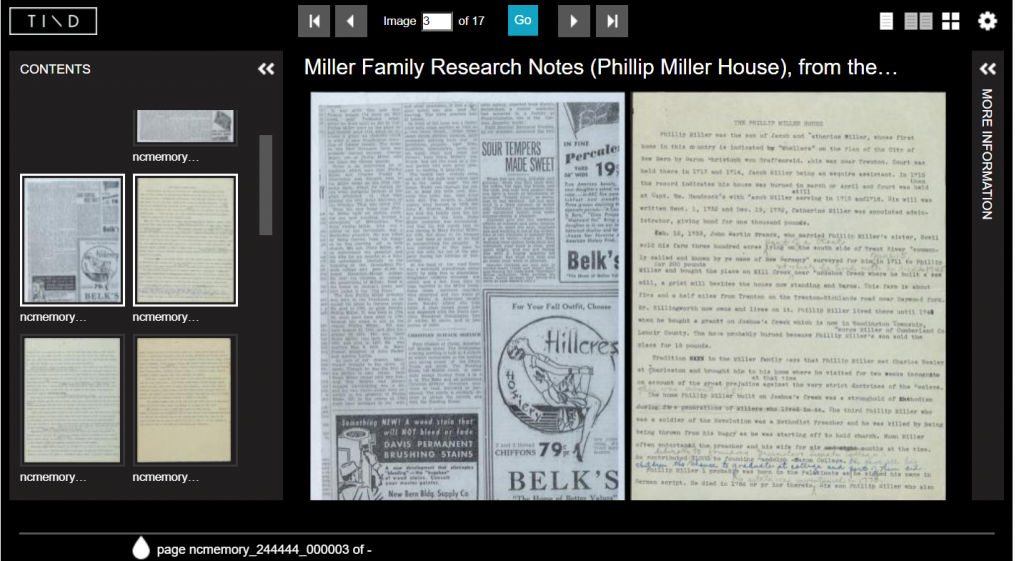
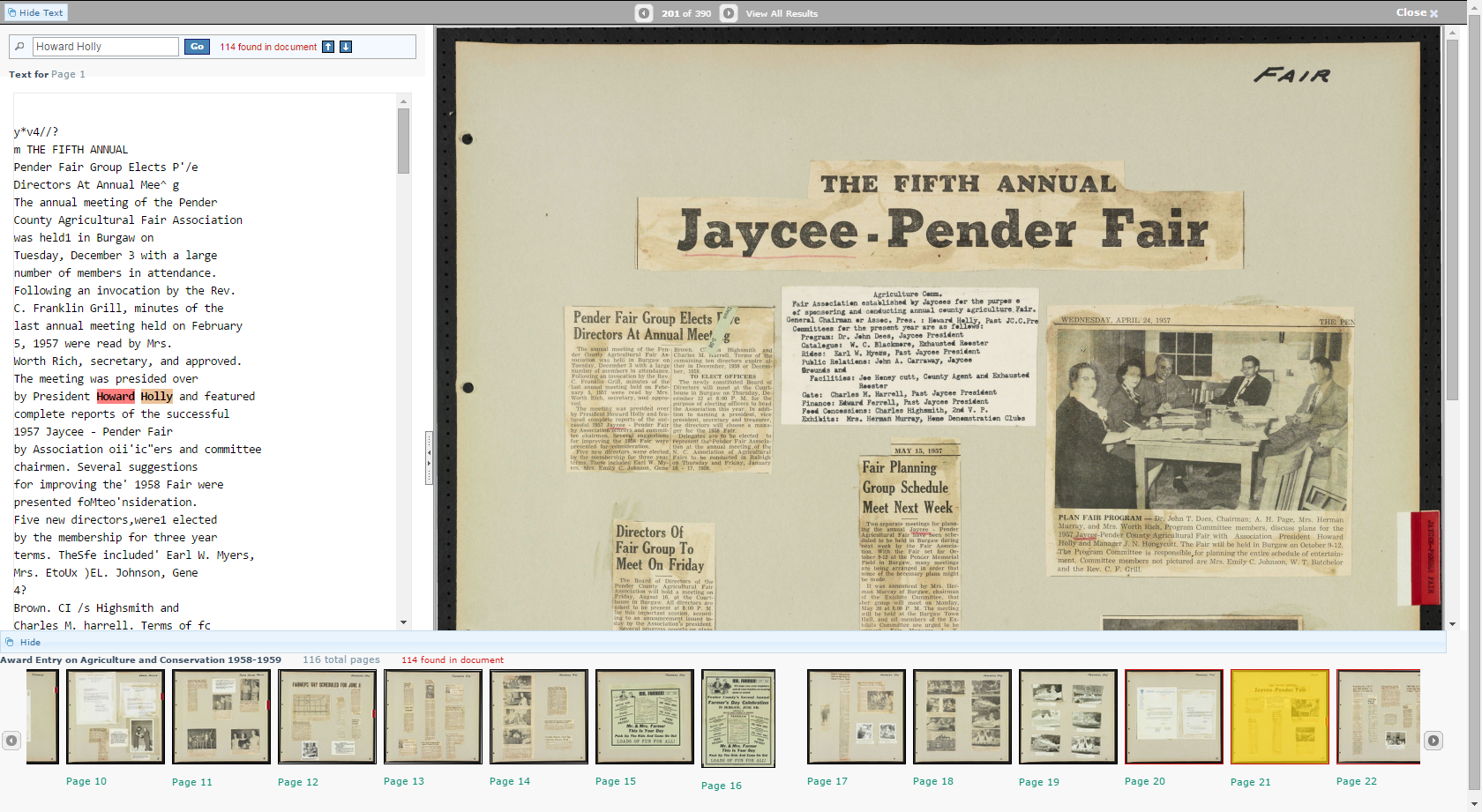
This screenshot shows a large view of a newspaper clipping alongside a typewritten manuscript from the Sybil Hyatt Papers. To the left are thumbnails showing other items in this particular file.
Keep in mind that both of these systems are made for hosting large numbers of special collections items and, like a library or museum catalog, cost money and staff to maintain. While it’s outside of the scope of this article, you can take a look at another post we did regarding how to share your digital files.
For any digitization project, we heartily recommend trying to find friends and peers at area or regional organizations. Ask if they have vertical files or digitization projects (or both?!). A quick phone call or email can help you avoid duplication of effort, at the least, and may gain you advice or a collaboration. You can even choose to share staff or other resources, or collaboratively apply for funding. We also like to be friends! If you’ve made it this far and still want to digitize, but you have questions or would like additional advice, feel free to get in touch.




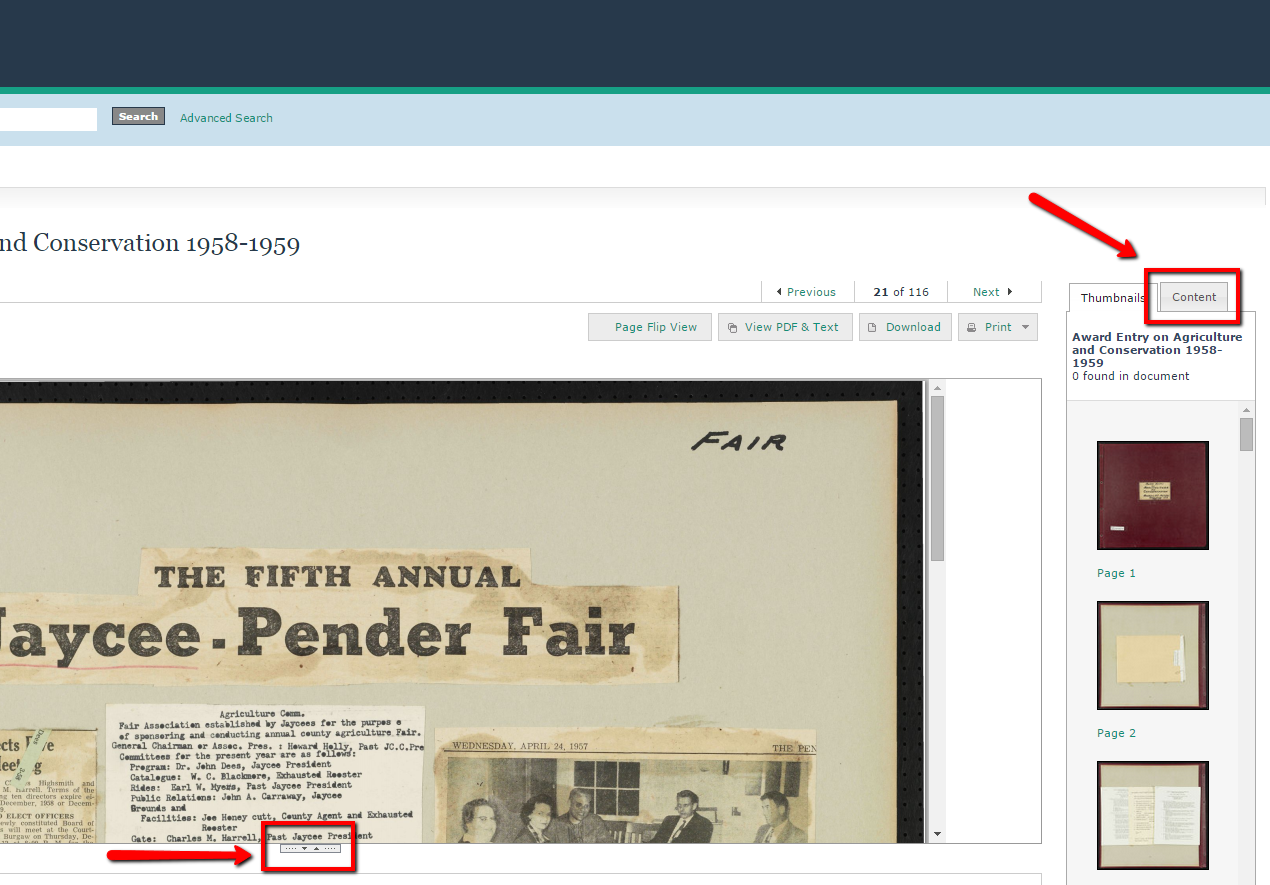
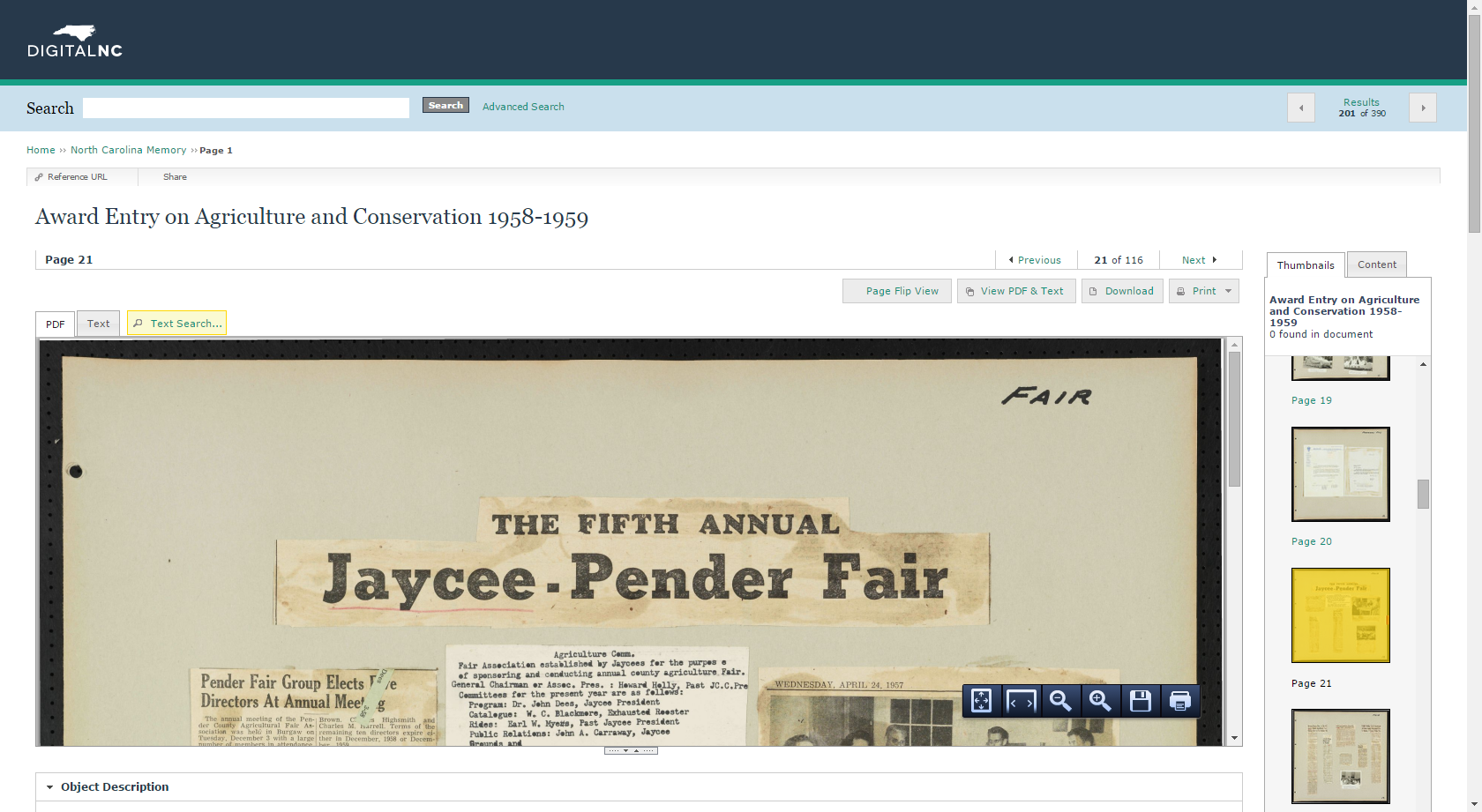 At default, maybe about one third of the scrapbook page is showing (your screen may vary from mine). To the right, only a few thumbnails are visible at any one time. To move back and forth between pages, you’ll need to scroll through and click on each thumbnail one by one. If you want to see the full text for items, you have to toggle back and forth between tabs. So, what are your options?
At default, maybe about one third of the scrapbook page is showing (your screen may vary from mine). To the right, only a few thumbnails are visible at any one time. To move back and forth between pages, you’ll need to scroll through and click on each thumbnail one by one. If you want to see the full text for items, you have to toggle back and forth between tabs. So, what are your options?