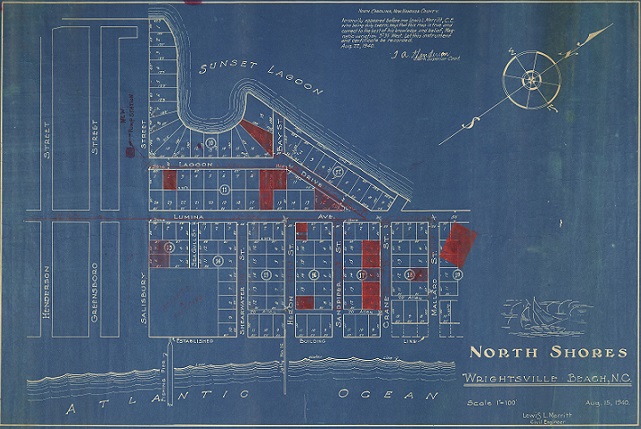
A blueprint of the North Shore of Wrightsville Beach, with buildings, pipes, and pump stations marked in red.
Over four dozen historical maps, blueprints, and more have been digitized and added to DigitalNC, courtesy of our new partner, the Wrightsville Beach Museum of History. These maps, some dating back to as early as 1923, cover many different parts of the Wilmington and Wrightsville Beach areas and really illustrate to us how wide and varied the geography of New Hanover County really is.
Many of the blueprints detail buildings around Wrightsville Beach, while others show plots of land and city streets. Several of the maps are designed to show specific buildings and building sites, such as the former Babies Hospital at Mott’s Creek in Wilmington. Others are geological cross sections, showing tide lines, jetty locations, and inlets along the coast. These are invaluable blueprints for tracking the coastline, as well as illustrating how the beaches and the towns around them have changed over time.
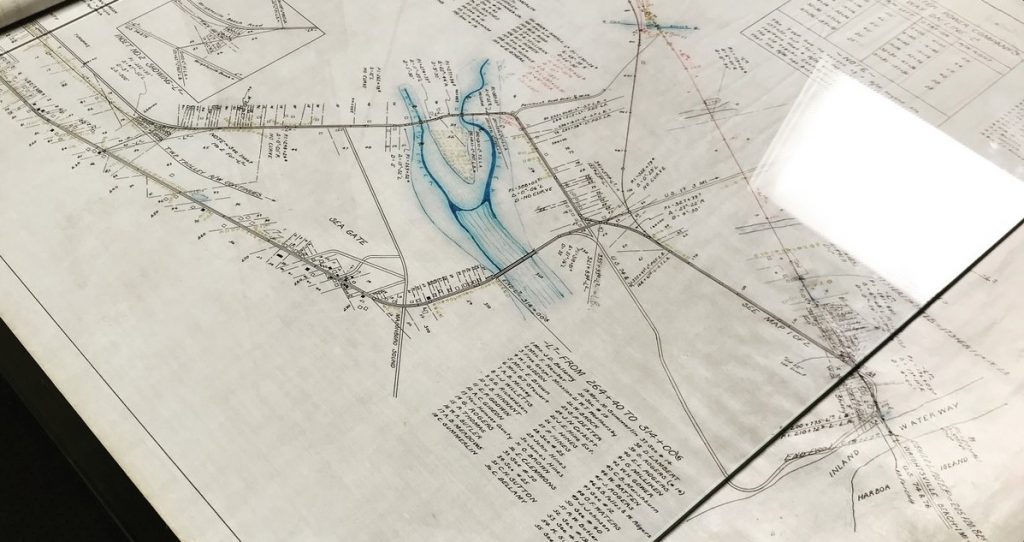
A photo taken during the mid-scanning process of one of the larger, composited maps of Wrightsville Beach
Many of these maps are massive, with some stretching to nearly 6 feet in length. A few of the aerial shots of Wrightsville Beach were even longer, requiring a small team to handle the map just to make sure it could be documented. As a result, it was a slow process for us to roll out these maps and blueprints, scan them using our overhead camera, composite them into complete shots, and prepare them for production. We have posted an instructional video on our Flickr page to show and explain how we scanned them. Many of them, including the aerial view of Wrightsville Beach, took 3 and sometimes 4 individual shots to stitch together, resulting in images that were sometimes over 8000 pixels high and over 10000 pixels wide.
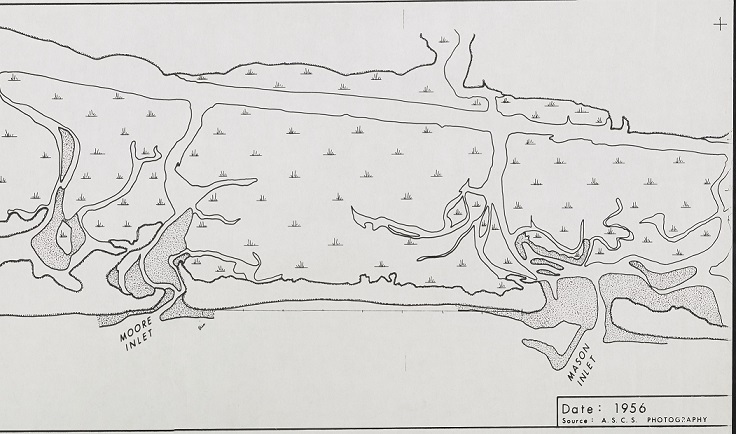
A portion of a 1956 map from the A.S.C.S. showing Moore Inlet and Mason Inlet.
These maps were in excellent condition, and we are honored in being able to digitize them and host them for everyone to see. To learn more about the Wrightsville Beach Museum of History, please visit their contributor page or their website.













 In July, the North Carolina Digital Heritage Center was pleased to welcome a group of middle school students from Williston Middle School and Friends School Of Wilmington. With them were writers Joel Finsel and John Jeremiah Sullivan and staff from the
In July, the North Carolina Digital Heritage Center was pleased to welcome a group of middle school students from Williston Middle School and Friends School Of Wilmington. With them were writers Joel Finsel and John Jeremiah Sullivan and staff from the 



